
Both Scala and Erlang employ the actor model, rather than threads, for concurrent programming. Innovations around the actor model aren't limited to just languages; the actor model is also accessible on Java-based actor frameworks like Kilim.
Kilim's approach to the actor model is intuitive, and as you'll soon see, the library makes building concurrent applications a breeze."
In 2005, Herb Sutter wrote a now famous article entitled, "The Free Lunch is Over: A Fundamental Turn Toward Concurrency in Software". In it, he tore apart the misplaced belief that Moore's Law would continue to unleash higher and higher CPU clock speeds.
Sutter predicted the end of the "free lunch" that had come of increasing the performance of software applications by piggy-backing on faster and faster chips. Instead, he said that obtaining an appreciable increase in application performance would require taking advantage of multicore chip architectures.
As it turns out, he was right. Chip manufacturers have hit a hard limit, with chip speeds stabilizing at around 3.5 GHz for some years now. Moore's Law is alive and well in the multicore arena with manufacturers increasing the number of cores on chips at an ever-increasing rate.
The basic programming model of languages. like the Java language, is thread based. While multithreaded applications aren't terribly hard to write, there are challenges to writing them correctly. What's difficult about concurrent programming is thinking in terms of concurrency with threads. Alternate concurrency models have arisen along these lines. One that is particularly interesting, and gaining mindshare in the Java community, is the actor model.Sutter also noted that concurrent programming would allow developers to take advantage of multicore architectures. But, he added, "we desperately need a higher-level programming model for concurrency than languages offer today."
The actor model is a different way of modeling concurrent processes. Rather than threads interacting via shared memory with locks, the actor model leverages "actors" that pass asynchronous messages using mailboxes. A mailbox, in this case, is just like one in real life — messages can be stored and retrieved for processing by other actors. Rather than sharing variables in memory, the mailbox effectively separates distinct processes from each other.
Actors act as separate and distinct entities that don't share memory for communication. In fact, actors can only communicate via mailboxes. There are no locks and synchronized blocks in the actor model, so the issues that arise from them — like deadlocks and the nefarious lost-update problem — aren't a problem. What's more, actors are intended to work concurrently and not in some sequenced manner. As such, actors are much safer (locks and synchronization aren't necessary) and the actor model itself handles coordination issues. In essence, the actor model makes concurrent programming easier.
The actor model is by no means new; it's been around for quite some time. Some languages, like Erlang and Scala, base their concurrency model on actors as opposed to threads. In fact, Erlang's success in enterprise situations (Erlang was created by Ericsson and has a rich history in the telecom world) has arguably made the actor model more popular and visible, and that has helped it become a viable option for other languages. Erlang is a shining example of the actor model's safer approach to concurrency.
Unfortunately, the actor model isn't built into the Java platform, but it is available to us in a variety of forms. The JVM's openness to alternate languages means that you can leverage actors via a Java-platform language like Scala or Groovy (see Resources to learn about Groovy's actor library, GPars). Also, you can try one of the Java-based libraries that enable the actor model, like Kilim.

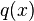 be a property provable about objects
be a property provable about objects  of type
of type  . Then
. Then 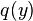 should be provable for objects
should be provable for objects  of type
of type  where
where